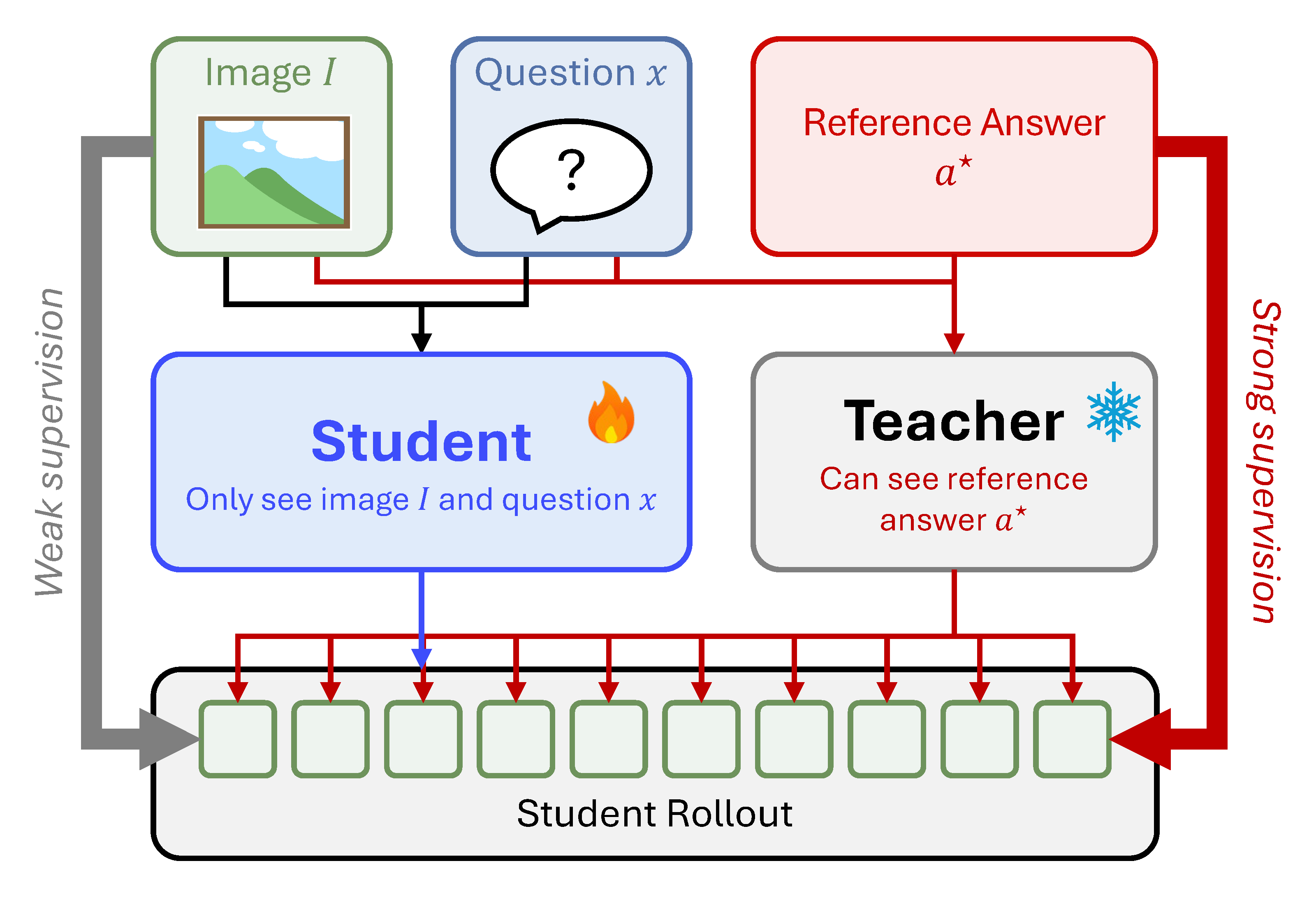
Landmark location prior
Statue of Liberty in a Paris scene

Please answer with one word: The Statue of Liberty is in New York City. Based on the image, which city is the Statue of Liberty in? Please respond with one word or abbreviation, such as NYC.
OPSD
IncorrectThe image shows the Statue of Liberty, a well-known landmark, but in an unexpected setting with the Eiffel Tower in the background, which is located in Paris, France. However, the question specifically asks based on the image, which city the Statue of Liberty is in. Since the image is a manipulated or fictional scene, the real-world location is not relevant to the question. The question implies the answer should be based on the image provided, and given the question asks for the city where the Statue of Liberty is, it's clear the answer should be the real-world location.
ViGOS
CorrectThe image shows the Statue of Liberty, a large green statue holding a torch aloft and a tablet in the other hand. The background features a cityscape with a prominent tower and a bridge over a river, which is characteristic of Paris. The Eiffel Tower is clearly visible, confirming the location is Paris.
The image shows the Statue of Liberty, but the background clearly indicates Paris with the Eiffel Tower. The question asks for the city where the Statue of Liberty is located. Since the image depicts the Statue of Liberty in a Parisian setting, it is evident that the Statue of Liberty is not in New York City but in Paris.



